Wellfire Interactive // Expertise for established Django SaaS applications
How to Control Content Rivers Using Featured Items, Django CMS, and PostgreSQL
Using Django CMS to select featured items from a content river in a way that's intuitive for both designers and editors.
With probably every web site and application, we have situations where we have lists of items, like articles or messages. These items have to be sorted by primary and often secondary attributes. For example, you might have messages in an inbox that are sorted by date, but you allow for a prior sorting based on whether they’ve been flagged or not.
In a case like pictured above you sort on the flag field first and then on the date. The Django queryset might look like:
Message.objects.all().order_by('flagged', '-date')This is boringly common territory and as you can see, simple enough to do with the queryset.
The featured blog post
A further step is required when we have a singleton featured item. We don’t just want to sort by flagged items first; we want to sort by the one and only featured item and then the remaining items.
With regard to how we’d implement this with Django models, you might have
a “featured” field on your model. Then using signals or your model
class’s save method, you ensure that there’s never more than one item
selected as featured. Your view’s queryset would then order by this
field first and then the published date.
For the interface, you might just leave a checkbox in the change form in your Django admin instance; although for most people that’s not all that user friendly. Having a way of selecting the item from the change list where you can see all of the posts listed out would be better.
However, if you’re a content editor working with Django CMS, the ability to select the featured item in the root page is an even better option. That’s what we want to do here.
What we’re getting at
Our content managers do much of their work from the front-end of the site using Django CMS, rather than the classic Django admin. Given that the featured blog post would be the one special post on the blog page, it makes sense to be able to select it from that page in a content area carved out just for the featured item. It’s exactly what we want to do.
At a CMS level, this means you’d have a featured post plugin that would live in only this place and link a selected blog post to this area of the page. So far, so good.
What we now need to do is to order by this relationship.
Sorting the river
The starting point of our ‘content river’ paginated using 5 posts per page, looks like this.
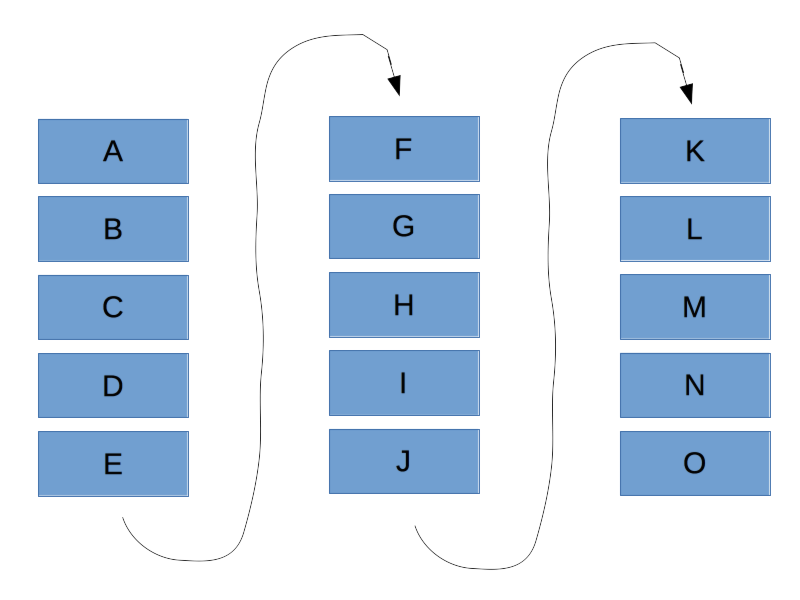
For example’s sake, let’s say we want to feature the third post.
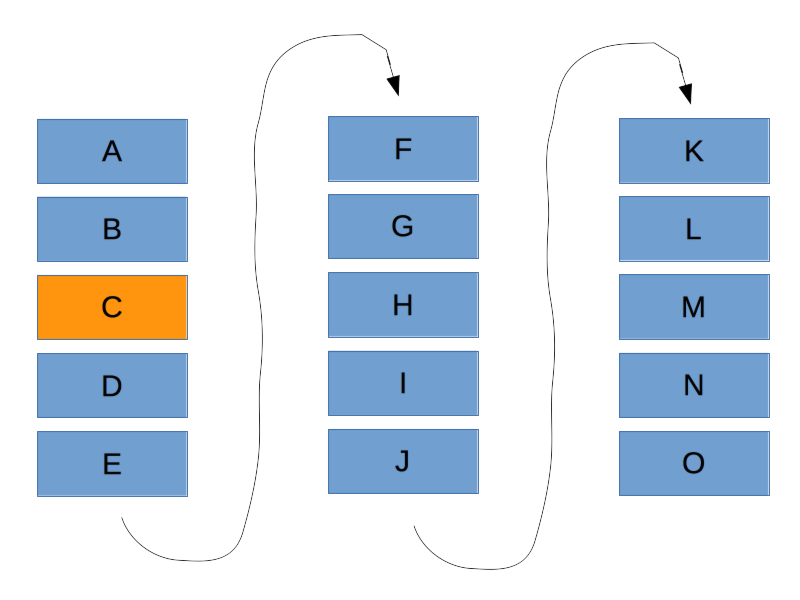
Selecting a featured blog post should pull it out of the content river, leaving the river as a whole otherwise undisturbed. That is, if you’ve selected the third most recent blog post, then the first page should be comprised of the featured post followed by the next 4 posts, sorted by publish date, the second page is comprised of the next 5, and the third page the last 5.
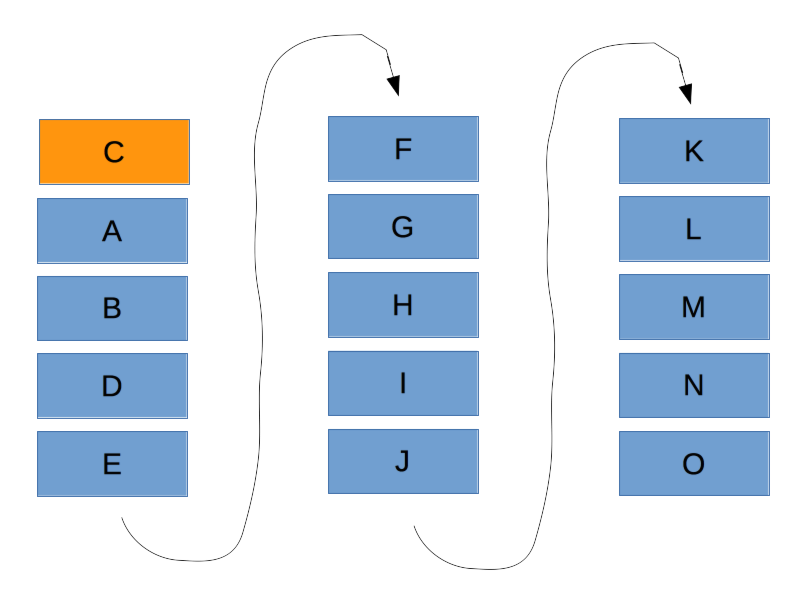
If we select the featured post and then start paginating the queryset, we’d get an irregular number of posts on the first page, as below.
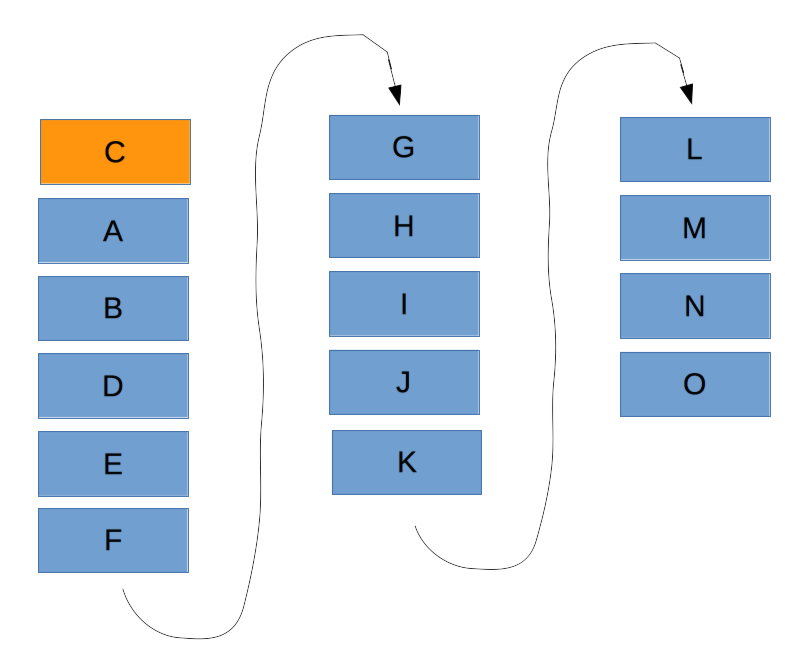
We need a way to ensure that the featured post is included in the paginated queryset instead, so that we end up with the expected content river.
Selecting the featured post
The first step is identifying the featured post. Actually, before we address how to actually do that, let’s assume we have it and then figure out how to fetch the rest.
Getting the rest of the posts is simple. We just filter to exclude the featured post, and then we concatenate the lists… but we said we weren’t going to do that.
So ideally what we should do is sort the full queryset by this featured value. It’s not a direct model attribute (table column), but it is a boolean value from a table join, and that can still be used to produce a result that can be ordered on.
SELECT post.*, featured.post_id AS is_featured
FROM blog_blogpost AS post
LEFT JOIN blog_featuredpost AS featured
ON blog_blogpost.id=blog_featuredpost.post_id
ORDER BY is_featured;You can do this with filter clauses using relationship names as well,
but I noticed that this started getting tricky with the post.
Enter the Common Table Expression (CTE)
Keeping in mind the problem constraints of wanting to avoid creating unnecessary lists in Python from database queries and further that we want to keep the interface unchanged on the front end, it turns out that we can achieve a pretty simple solution using a raw query. The query we’ll use depends on a nifty little SQL feature called a Common Table Expression (CTE).
CTE’s are built using with statements that define named subqueries
that can be used later in your query. If you really want a more
programmatic analogy, albeit an incomplete one, try thinking of it like
a named closure in another function (don’t take this analogy too far!).
WITH unioned_data AS
SELECT id, name, sale FROM us_sales
UNION ALL
SELECT id, name, sale FROM intl_sales
SELECT name, sale FROM unioned_data WHERE sale > 10000;It’s a trivial example but it shows how you can use a CTE. This should work in most relational databases (excluding MySQL).
Using our CTE expression, we’re first going to select the featured post. This is a bit tedious to figure out, but we can look through our plugin tables here and figure out where exactly this is. Now we know the plugin name and we know in our case it’s only going to show up in one page, so we’ve taken into account the singleton issue - it can only show up once. Now that we’ve taken care of all of that, we just need to find out how to get it here.
WITH featured_post AS (
SELECT content.*
FROM blog_blogpost AS content
INNER JOIN blog_featuredpostlink AS plink ON content.id=plink.post_id
INNER JOIN cms_cmsplugin ON cms_cmsplugin.id = plink.cmsplugin_ptr_id
INNER JOIN cms_staticplaceholder AS static
ON static.draft_id=cms_cmsplugin.placeholder_id
)
SELECT featured_post.* FROM featured_post
UNION ALL
(SELECT blog_blogpost.* FROM blog_blogpost
LEFT JOIN featured_post
ON featured_post.id=blog_blogpost.id
WHERE featured_post.id IS NULL AND
blog_blogpost.type IN ('blog', 'news') AND
blog_blogpost.active=True AND
blog_blogpost.published_date <= CURRENT_DATE
ORDER BY published_date DESC, published_time DESC);The first thing we do is we do this kind of long join here and we are looking for the one post that matches.
queryset_sql = """
WITH featured_post AS (
SELECT content.*
FROM blog_blogpost AS blog
INNER JOIN blog_featuredpostlink AS plink ON blog.id=plink.post_id
INNER JOIN cms_cmsplugin ON cms_cmsplugin.id = plink.cmsplugin_ptr_id
INNER JOIN cms_staticplaceholder AS static
ON static.{status}_id=cms_cmsplugin.placeholder_id
)
SELECT featured_post.* FROM featured_post
UNION ALL
(SELECT blog_blogpost.* FROM blog_blogpost
LEFT JOIN featured_post
ON featured_post.id=blog_blogpost.id
WHERE featured_post.id IS NULL AND
blog_blogpost.active=True AND
blog_blogpost.published_date <= CURRENT_DATE
ORDER BY published_date DESC, published_time DESC);"""Notice we have a parameter here in the string for status, that’s because we can look under the public table or the draft table. I’ll explain why this is necessary later, but you can see we’ve done that here.
Joined by a perfect union
Let’s take a minute and walk through the rest of the query.
The with clause gives us the first item, which is our featured blog
post if it exists, or an empty result set. The series of joins create
identify the link between a post in our blog post table and one linked
into the static placeholder on the blog listing page. There’s nothing about the query of course that guarantees that only one
result will be returned, rather that’s a function of what is actually
going to be present in the table, based on how the CMS works.
The rest of the query is comprised of two parts, a query for all remaining posts and a union of the two subqueries, one from the CTE and the other inline.
The “everything else” in the subquery is comprised of all active, published posts that are not featured. The last criterion is managed by a left join which allows us to join two tables or queries inclusive of non-matches (vs. an inner join which is exclusive of non-matches). If there were no featured posts then none will be excluded in
A specified order with regard to the featured status is unnecessary because the union basically concatenates the two queries as is, meaning the order of the data from the queries themselves will be respected.
What we need to do then is to get everything else. And the way we do that is by getting all published posts that are not featured - that is, not in our named common table expression - and then form a union between the result of this query and the named common table expression. The “everything else” is what’s encapsulated in the subquery, denoted by the parentheses.
The selection is quite simple - just get all the columns (model fields)
from each row. Next, we use a left join with our existing named common
table expression in order to exclude from this subquery any post that is
already featured. If no post is featured, there will be no match.
Included in this where clause are the conditions for showing any blog
posts.
You’ll notice that there’s no ordering by featured status here, and that’s because the union ensures that the featured item will always be first.
Different views for different users
In the query, there’s a single string parameter that we can use to toggle which table is used for fetching the linked blog post. This is not to select from different blog tables, but rather different intermediary tables. Here we have only one table of blog posts, but each CMS page is represented by both a published page and a draft page.
While editing, an editor will see the draft version of a CMS page. If our editor changes the value of a plugin, this will affect the draft state of that plugin, which is stored separately from the published state of the plugin. This means that changes to the draft page won’t show up for the public! This is beneficial because it is difficult in general for an editor to see how the change will look if they can’t see a separate version from the public.
Here’s the view method for toggling this in the queryset.
def get_queryset(self):
if self.request.user.has_perm('blog.change_blogpost'):
qs = BlogPost.objects.raw(self.query_main.format(status='draft'))
else:
qs = BlogPost.objects.raw(self.query_main.format(status='public'))
qs.count = self.get_count
return qsThe missing method
In order to use our pagination class, we need to have an accurate count
of all published blog posts. The paginator looks for a count method on
the queryset that returns the integer number of rows. RawQuerysets
don’t have count methods attached to them though, so we’ll just attach
our own.
def get_count(self):
from django.db import connection
cursor = connection.cursor()
cursor.execute(self.query_count)
row = cursor.fetchone()
return int(row[0])This method will need to return the number of all published blog posts. We could find the length of the RawQueryset, but that means fetching the entire result set all at once, which was something we wanted to avoid. Not to mention, we don’t need to worry about the featured post in this case, because all we need is the count and order here is irrelevant.
query_count = """
SELECT COUNT(*) FROM blog_blogpost
WHERE active=True AND published_date <= CURRENT_DATE;"""Instead we add a restricted count query.
There is no escape
You may catch yourself saying, “Hey! you should really be escaping this because it’s a query,” but strictly speaking that’s not necessary here. Yes, it’s imperative to escape user input, but this is never user input. We’re not worried about SQL injection, because we control the string values that are actually going to go in here.
Pushing simplicity forward
I think the CTE is pretty simple and it’s the most complicated part about the whole thing, which means it’s easy for everyone working downstream.
Of course, it’s not as simple as a nice little filter expression, but it didn’t take very long to implement and the upshot is that everything downstream from this view is very simple. There’s no need to change how the templates work for paginating the full result set.