Wellfire Interactive // Expertise for established Django SaaS applications
An Illustrated Git-based Development Workflow
A sensible Git-based workflow for small teams and open source projects.
Questions of workflow and process have a habit of sneaking up on us, often only after a team has grown or something very bad wrong has happened. “How are we going to ensure we’re all working from the same base?” “How did this change get so f&!@# up?” The whole development process includes everything from working with the client (if that’s what you do) to turning requirements into code and deploying updates. But limiting ourselves to just that piece where people write code and exchange updates, there’s a lot of room to reduce problems and make life better by setting out a sensible development workflow and sticking to it.
The workflow in question is one of many you could pick, and it’s based on what’s worked in a subset of all possible situations (in only one possible world). This workflow is called the “Integration Manager” workflow on the Git site. This is a really good workflow for most open source projects, and it lends itself nicely to small teams (100’s of developers? maybe not).
We take the the philosophy that much of what’s good for open source projects applies to proprietary projects, too. That includes documentation, code standards, testing, and of course, workflow. The main difference between the example here and the example on the Git site is the focus on branches here, not just forks. In addition, there’s an implicit understanding that changesets get lumped togehter, rebased, into the master branch. It matters more that the history is ordered by when commits were applied to the canonical master branch than that they’re ordred in historical sequence.
Here’s the illustrated John Madden overview:
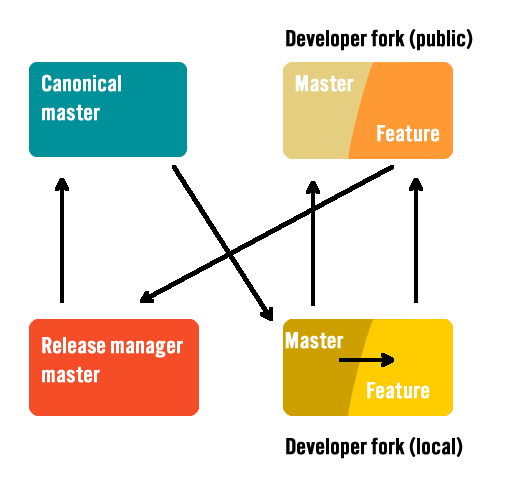
Ignore the arrows for a moment. In the overview above, we see four repositories, or forks:
- The canonical/blessed repository (remote)
- The release manager’s repository (local)
- A developer’s repository (local)
- The same developer’s public repository (remote)
So why not just push and pull from a shared repository? In many cases that’s fine, but here the goal is to enforce both code and commit quality. It makes it easier to have multiple features or fixes done in parallel, and in isolation, and applied as they’re ready to be accepted.
Start with an updated master branch
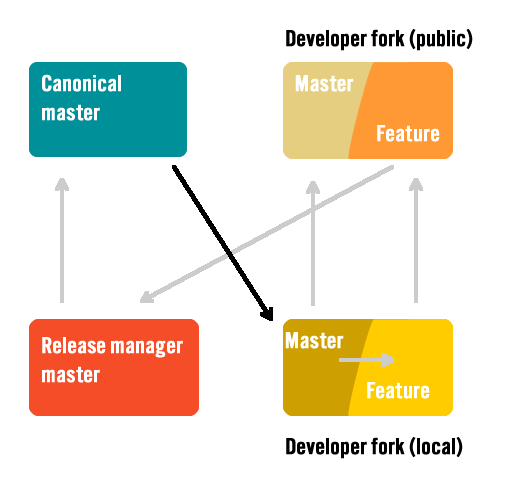
Hopefully the obvious step, but before starting a new fix or feature, the developer updates his local developer master by fetching any new commits from the canonical master branch. Both the code and the history should be the same.
Branch cleanly from master
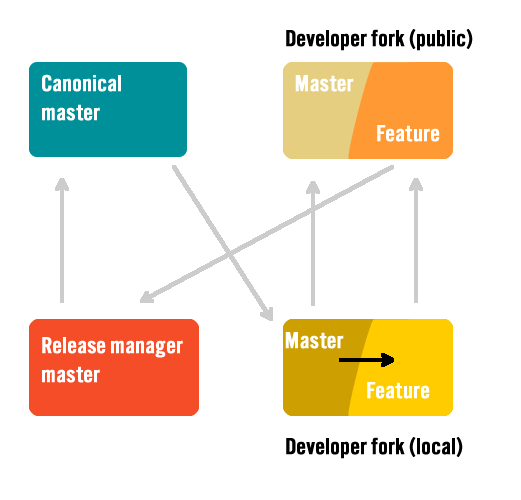
Every feature or fix - any change - is created by branching off the canonical master branch. Always! And each feature or fix in its own branch.
Publish to a remote feature branch
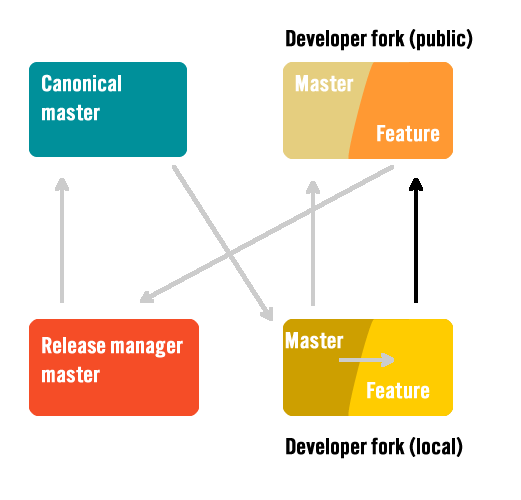
Once the update is ready for production it should be pushed to the developer’s remote, to the same named branch, it not already. If the update was not yet published then its appropriate to rebase newer changes from the master branch.
Pull request to release manager
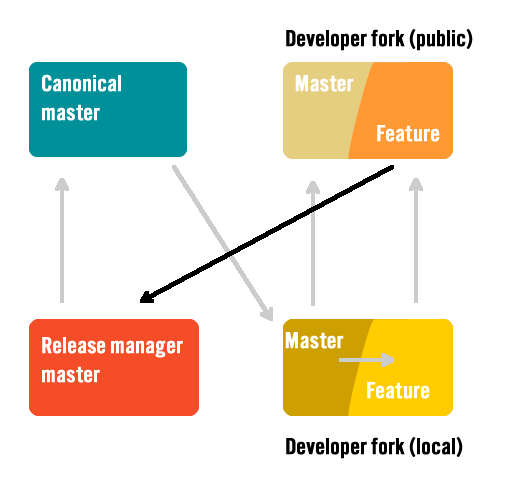
Once the changes have been verified and published by the developer, the developer should initiate a pull request to the release manager. The request should include only commits with explicit changes by the developer to modify the codebase related to the fix or feature. It should not include any merge commits from master. If the code is behind master, rebasing can be left to the release manager or, if severly behind, the develop should rebase master changes before publishing and issuing the pull request.
Test and publish to remote master
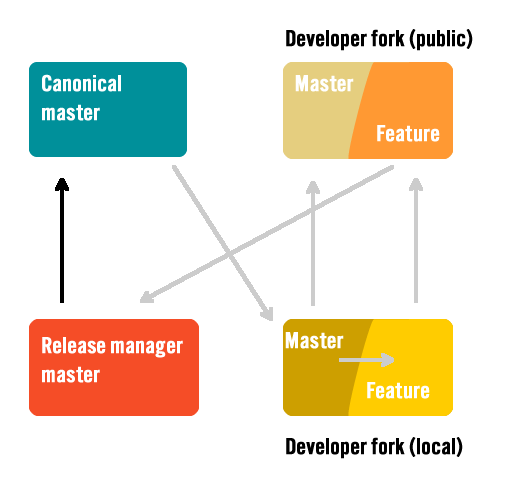
If you’re not using a CI system, the release manager should checkout a local copy of the new feature and run any tests before merging it into master. Better to find them now than later. In the event of failing tests or other issues noticed in review, the release manager should have the developer fix those issues.
If the tests pass she should rebase any changes from master and then merge into master before pushing to the canonical repository. If there were any conflicts running the tests again isn’t a bad idea before pushing.
Resync local master
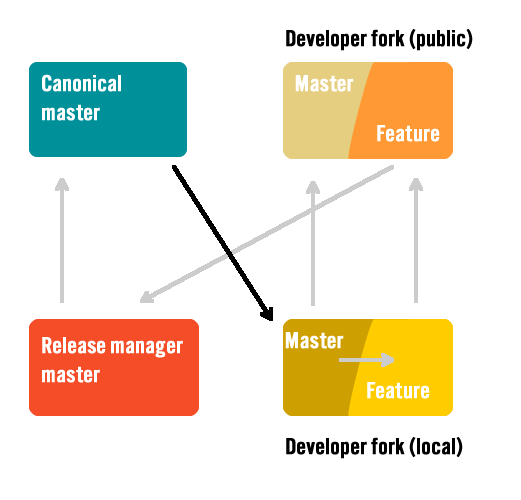
The developer’s local master should be refreshed with the latest changes from the canoncial master. This ensures that when creating new features/fixes or running the server the code is up to date.
Note that this branch is always updated from the canonical master (remote) and not by merging any local branches. This would get the developer’s local master branch out of sync and begin to introduce extraneous changesets later.
Keep remote master updated
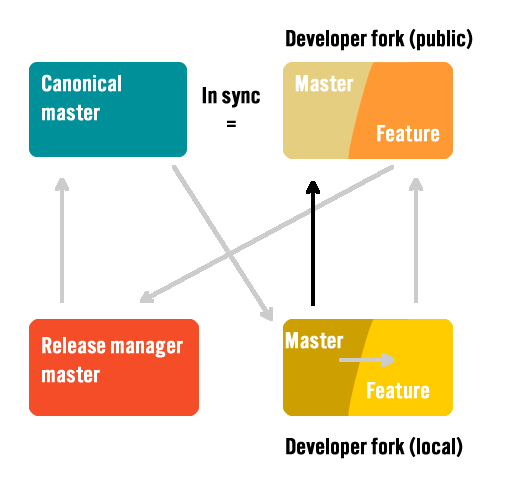
The developer’s remote master can now be updated. This isn’t a consequential step but can reduce confusion and create a good point in time reference.